 Maybell's Blog
Maybell's BlogLearning how your Machine Learns

At the mention of the term "Machine Learning Algorithms", lots of people get overwhelmed or sometimes scared of what seems like rocket science or something made for a Brainiac (similar to Brainy of The Pinky and the Brain Animes🤣🤣).
Alright, return from the flashback and let's understand what "Machine Learning Algorithms" means by breaking the term into units.
Machine Learning - simply means a computer observing the rate of occurrence of events in order to act on its own later.
Algorithms - simply means procedures, processes or techniques.
Bringing the units together, Machine Learning Algorithms are procedures or techniques used by computers to observe the rate of occurrence (especially in data) for intelligent imitation. Simply put, ML algorithms are the instructions behind how computers make inferences and decisions on their own with very little or no human interference. Algorithms here are various statistical and mathematical operations.
In a previous article, I discussed the rudiments of Data Science of which Machine Learning Modeling is a part of.
This article will dwell on:
- The categories of machine learning algorithms and their real life applications
- Types of ML data
- Types of ML problems
Categories of Machine Learning Algorithms
Generally, ML Algorithms are categorized into three, depending on the nature of the data(labeled or unlabeled) and the result intended.
They are:
Supervised Learning
This type of ML algorithms is one of the basic types of ML as it has to do with labeled data. Labeled data here, means that every input data point in the dataset has a corresponding output data point.
Supervised learning entails training your ML algorithms on the labeled data. This is how it works, the labeled data is split into training and test datasets respectively. The supervised ML Algorithm is trained on the training data set after which the test data is used to check if truly the algorithm learned well.
Just like in a classroom where the teacher gives several examples to explain the subject topic to the students after which the students are given class works or assignments to prove their knowledge of the topic. The more assignments done correctly, the more knowledge. Same goes for supervised learning; the more data it tests on, the better it becomes at observing new occurrences.
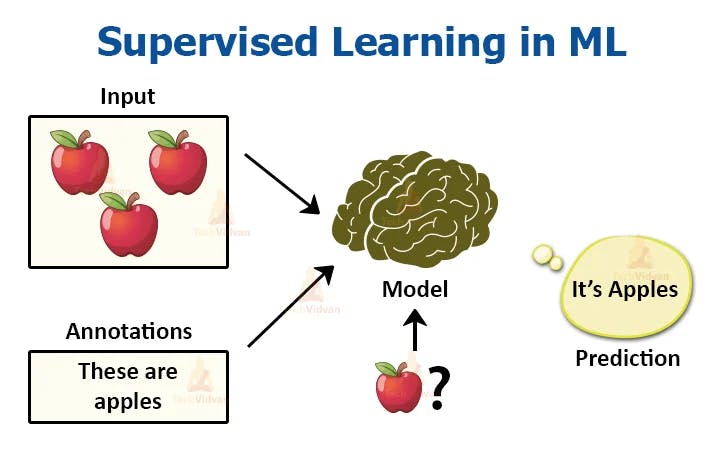
In real life applications, supervised learning algorithms are employed in Face Detection, Text recognition, Weather Forecasting, Stock Prediction etc. Some examples of supervised learning algorithms are Random Forest, Linear Regression , support vector machine etc.
Unsupervised Learning
On the other hand, Unsupervised Learning Algorithms deals with unlabeled data. In this case the algorithm learns to find the relationship between data points on its own. Real life applications of Unsupervised Learning Algorithms includes Fraud Detection, Product Segmentation, Similarity Detection etc.
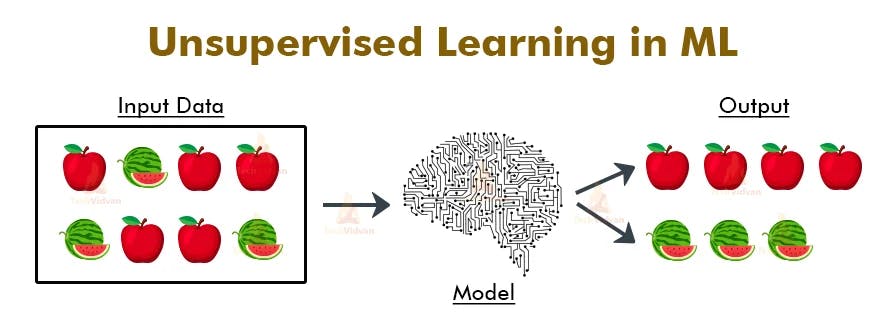
Examples of Unsupervised Learning Algorithms are K-means Clustering, K-Nearest neighbor, Gaussian Mixture Model etc.
Reinforcement Learning
This ML algorithm works on trial-and-error method and keeps getting better with more successful trials. Technically, Reinforcement Learning involves agent, actions, environment, interpreter and rewards and punishment. The agent takes actions in the environment and is being rewarded or punished depending on the outcome of the actions.
So, the more the algorithm learns the environment successfully, the more it is rewarded in the form of using the successful algorithm again.
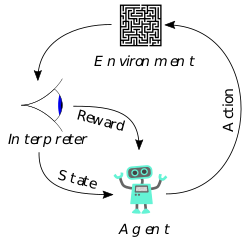
It is similar to driving through a route often and being familiar with the curves and bumps on that route. Or better still, buying a kid some chocolates for always coming top in Arithmetic class and using that kid as an example to his peers.
In real life, Reinforcement Learning is applicable in Robotics, Natural Language Processing (NLP), Self-driving Cars, Finance and Trading, Healthcare, Gaming, etc.
Some examples of Reinforcement Learning Algorithms are: Support Vector Machine (SVM), State Action Reward State Action(SARSA),Deep Q Network etc.
Types of Machine Learning Problems
Before selecting a machine learning algorithm to use for your dataset, you should know the kind of the problem you're trying to solve with your dataset. Each ML algorithm listed above has the kind of problems they are best tailored for.
Machine Learning Problems:
Machine Learning problems can be classified based on the Machine Learning Categories.
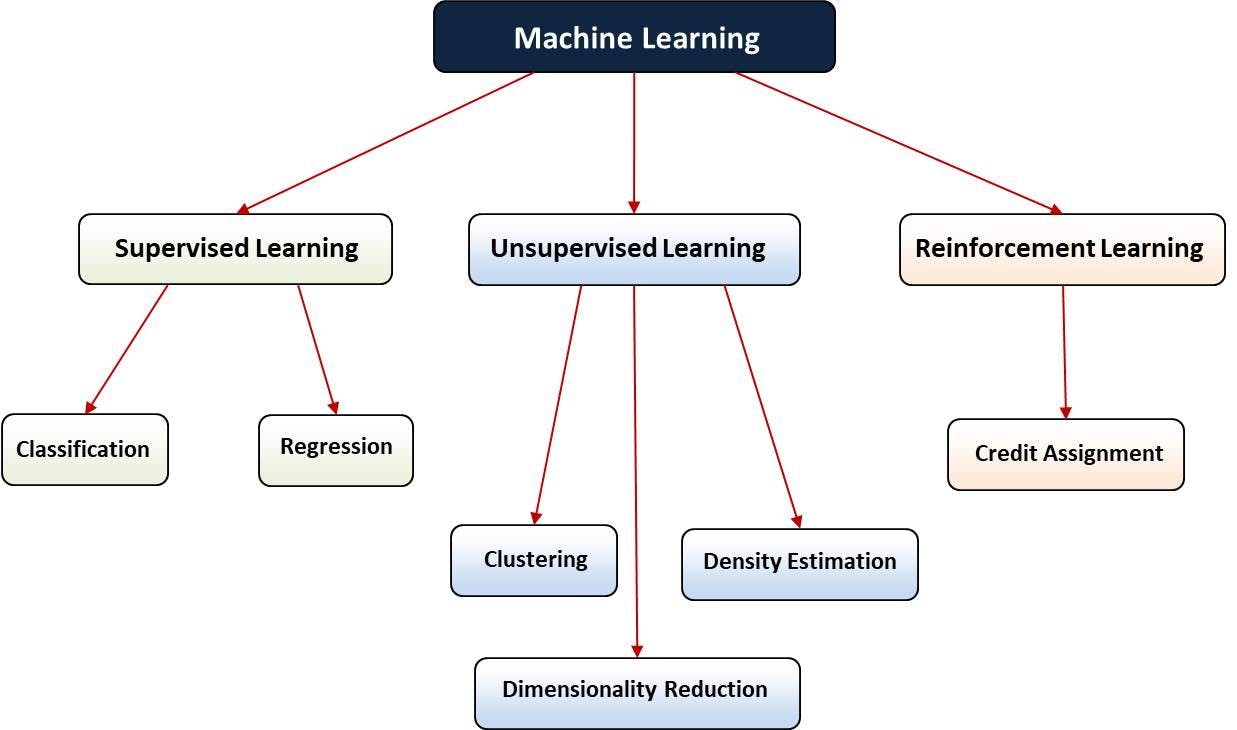
Supervised Learning
- Classification
- Regression
Unsupervised Learning
- Clustering
- Anomaly Detection
Classification
Classification refers to grouping of data points based on their identity. For instance, you receive emails from those you subscribed to and the ones you didn't subscribe to. You can group the subscribed ones as non-spam since you are aware of them and group the unsubscribed ones as spam because you don't know where they come from. In ML classification problems, data are labeled. Support Vector Machine is a popular algorithm used for classification problems.
Regression
Regression problems are problems involving continuous or real variables. This means that the variables continue to change from time to time. For instance ; weight, sales revenue, etc.
In regression, the problem is solved using the technique of dependent variable(X) and independent variable(Y). A change in Y affects X. In simple terms, X is the continuous value you are trying to predict while Y is the variable you control to get a change in X. Using the analogy of water, the more water (Y) you drink, the healthier(X) you become. Linear Regression is the most common algorithm to solve regression problems
Clustering
Clustering problems involve having large datasets with several data points which are not exactly the same but similar. Hence, the similar data points are grouped into small clusters based on their traits, and other features used measure their similarities. Clustering is a type of unsupervised learning used in grouping unlabeled data. So, when you have a large dataset with no labels, the best method to use is clustering. Popular clustering algorithm of unsupervised learning is the K- means clustering.
Anomaly Detection
Sometimes, data points do not fit into clusters or patterns, this is where anomaly detection comes in. Anomaly detection involves identifying data points that do not conform to the dataset’s pattern. Iit is a type of unsupervised learning and it is largely employed in medical diagnosis and fraud detection. Anomalies are also referred to as outliers. Isolation Forest is an algorithm for anomaly detection.
Conclusion
Finally, you made it to this point!
I must congratulate you for choosing to read through the technical terms and I'm sure you got value. You have learned basic procedures to build machine learning models through the knowledge of algorithms.
In subsequent articles, I’ll dive deeper into using ML algorithms to solve one or more common problems.
Meanwhile, this article is an appetizer, if you seek to get the main meal, ensure to pick one of the courses available online or onsite and devote time to practicing.